1. Scientific and technical products prepared as a result of the project implementation:
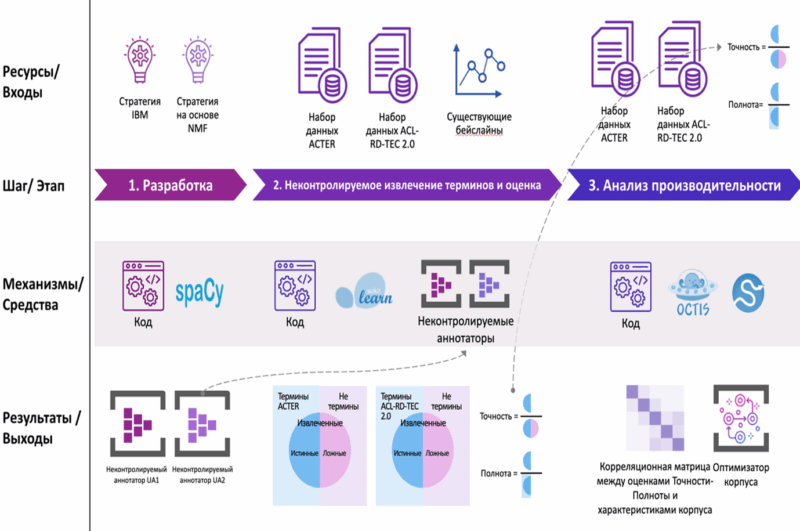
- Effective unsupervised annotators UA1 and UA2 were developed.
- Performance estimates of the annotators UA1 and UA2 on the ACTER and ACL RD-TEC 2.0 datasets were obtained.
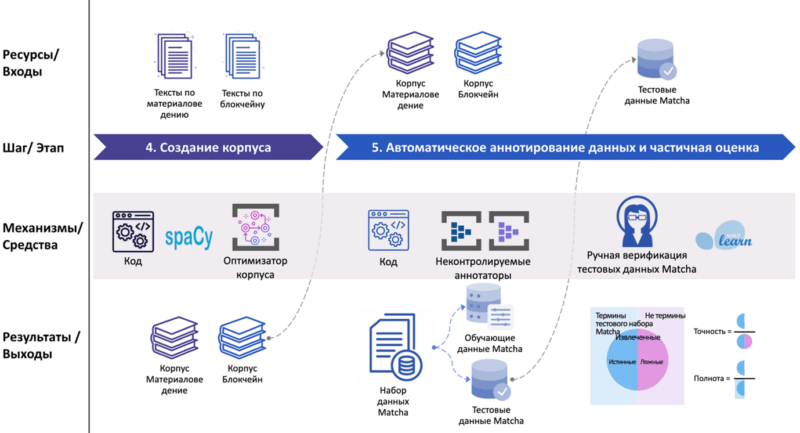
- An effective text corpus optimizer was developed.
- The Matcha dataset was created in the Materials Science and Blockchain domains in English and Kazakh.
- The performance of the annotators UA1 and UA2 on the test subset of the Matcha dataset was estimated.
- A new term extraction method T-Extractor was developed.
- Разработан новый метод извлечения терминов T-Extractor.
2. Scientific publications:
1. Semantic Non-Negative Matrix Factorization for Term Extraction
This study introduces an unsupervised term extraction approach that combines non-negative matrix factorization (NMF) with word embeddings. Inspired by a pioneering semantic NMF method that employs regularization to jointly optimize document–word and word–word matrix factorizations for document clustering, we adapt this strategy for term extraction. Typically, a word–word matrix representing semantic relationships between words is constructed using cosine similarities between word embeddings. However, it has been established that transformer encoder embeddings tend to reside within a narrow cone, leading to consistently high cosine similarities between words. To address this issue, we replace the conventional word–word matrix with a word–seed submatrix, restricting columns to ‘domain seeds’—specific words that encapsulate the essential semantic features of the domain. Therefore, we propose a modified NMF framework that jointly factorizes the document–word and word–seed matrices, producing more precise encoding vectors for words, which we utilize to extract high-relevancy topic-related terms. Our modification significantly improves term extraction effectiveness, marking the first implementation of semantically enhanced NMF, designed specifically for the task of term extraction. Comparative experiments demonstrate that our method outperforms both traditional NMF and advanced transformer-based methods such as KeyBERT and BERTopic. To support further research and application, we compile and manually annotate two new datasets, each containing 1000 sentences, from the ‘Geography and History’ and ‘National Heroes’ domains. These datasets are useful for both term extraction and document classification tasks. All related code and datasets are freely available.
Nugumanova A. et al. Semantic Non-Negative Matrix Factorization for Term Extraction //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 7. – С. 72. doi.org/10.3390/bdcc8070072.
2. QA-RAG: Exploring LLM reliance on external knowledge
Large language models (LLMs) can store factual knowledge within their parameters and have achieved superior results in question-answering tasks. However, challenges persist in providing provenance for their decisions and keeping their knowledge up to date. Some approaches aim to address these challenges by combining external knowledge with parametric memory. In contrast, our proposed QA-RAG solution relies solely on the data stored within an external knowledge base, specifically a dense vector index database. In this paper, we compare RAG configurations using two LLMs—Llama 2 7b and 13b—systematically examining their performance in three key RAG capabilities: noise robustness, knowledge gap detection, and external truth integration. The evaluation reveals that while our approach achieves an accuracy of 83.3%, showcasing its effectiveness across all baselines, the model still struggles significantly in terms of external truth integration. These findings suggest that considerable work is still required to fully leverage RAG in question-answering tasks.
Mansurova A., Mansurova A., Nugumanova A. QA-RAG: Exploring LLM reliance on external knowledge //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 9. – С. 115. doi.org/10.3390/bdcc8090115.
3. Development of a question answering chatbot for blockchain domain.
Large Language Models (LLMs), such as ChatGPT, have transformed the field of natural language processing with their capacity for language comprehension and generation of human-like, fluent responses for many downstream tasks. Despite their impressive capabilities, they often fall short in domain-specific and knowledge-intensive domains due to a lack of access to relevant data. Moreover, most state-of-art LLMs lack transparency as they are often accessible only through APIs. Furthermore, their application in critical real-world scenarios is hindered by their proclivity to produce hallucinated information and inability to leverage external knowledge sources. To address these limitations, we propose an innovative system that enhances LLMs by integrating them with an external knowledge management module. The system allows LLMs to utilize data stored in vector databases, providing them with relevant information for their responses. Additionally, it enables them to retrieve information from the Internet, further broadening their knowledge base. The research approach circumvents the need to retrain LLMs, which can be a resource-intensive process. Instead, it focuses on making more efficient use of existing models. Preliminary results indicate that the system holds promise for improving the performance of LLMs in domain-specific and knowledge-intensive tasks. By equipping LLMs with real-time access to external data, it is possible to harness their language generation capabilities more effectively, without the need to continually strive for larger models.
Mansurova A., Nugumanova A., Makhambetova Z. Development of a question answering chatbot for blockchain domain //Scientific Journal of Astana IT University. – 2023. – С. 27-40. doi.org/10.37943/15XNDZ6667.
4. Evaluation Of IBM’s Proposed Term Extraction Approach On The ACTER Corpus
Automated term extraction seeks more efficient and precise methods. IBM researchers have proposed an unsupervised annotator aimed at extracting highly technical domain terms. This approach utilizes sentence encoders and analysis of morphological signals, term-to-topic relationships, and similarities within terms. In this paper, we attempt to realize this method proposed by IBM from scratch and conducted testing using the ACTER dataset. Additionally, in our experimentation, we include an analysis of extracting incorrect n-grams that may adversely affect the quality of the unsupervised annotator. Our recreated method has demonstrated an F1-score of 44.8% and a loss of 5.15% compared to the IBM approach on the ACL-RD-TEC 2.0 dataset. On the ACTER dataset, our metrics show similar results to other advanced methods in the field performed on this dataset.
Kalykulova A., Kairatuly B., Rakhymbek K., Kyzyrkanov A., Nugumanova A. Evaluation Of IBM’s Proposed Term Extraction Approach On The ACTER Corpus // IX — International Scientific Conference «Computer Science and Applied Mathematics». – Almaty: Institute of Information and Computational Technologies CS MSHE RK, 2024. – С. 597–604. https://conf.iict.kz/wp-content/uploads/2025/01/collection_CSAM_IX_2024.pdf
5. Evaluation and comparison of the quality of word embeddings
This article explores approaches to evaluating embedding quality, which can be divided into intrinsic and extrinsic methods. Intrinsic methods assess representations independently of specific tasks, while extrinsic methods rely on NLP tasks for evaluation. Particular attention is given to the evaluation of semantic similarity using datasets such as WordSim-353, SimLex-999, and SimVerb-3500. Pretrained models FastText and SentenceBERT were used for the evaluation. The results show that FastText models demonstrate high correlation scores and outperform SentenceBERT in representing individual words. Although SentenceBERT offers advantages in tasks like semantic similarity search and clustering, it is less effective for individual word representation. The choice of model should be based on empirical evidence and the specific requirements of the task.
Альжанов А. М., Рахымбек К. К. Оценка и сравнение качества эмбеддингов слов // Проблемы оптимизации сложных систем: Материалы XX Междунар. Азиат. школы-семинара. – Алматы, 2024. – С. 211–215. https://conf.iict.kz/wp-content/uploads/2024/09/opcs_material_2024.pdf.
6. T-Extractor: A Hybrid Unsupervised Approach for Term and Named Entity Extraction Using Rules, Statistical, and Semantic Methods
Automatic term extraction is a key technology for optimizing natural language processing tasks such as machine translation, sentiment analysis, knowledge graph construction, and/or ontology population. This study presents the T-Extractor approach for unsupervised term extraction. The research goal is to develop an efficient method that does not require labeled data, and to analyze its applicability on scientific texts. T-Extractor combines rule-based, statistical, and semantic analysis, treating unigram and phrase extraction as two subtasks. Part-of-speech templates are used in the candidate selection phase, while a filter based on raw and rectified frequencies refines phrase boundaries. TopicScore is applied for final term filtering, improving extraction precision. Additionally, simple rules help identify abbreviations and named entities, improving recall. T-Extractor was tested on the ACTER (three languages, four domains) and ACL RD-TEC 2.0 datasets. In English, the best result was achieved in the equi domain, with an F1- measure of
48.5%, precision of 41.6%, and recall of 58.2%. On the ACTER dataset, the approach outperformed existing unsupervised methods and performed better than the supervised GPT-3.5-Turbo and BERT models in the corp and wind domains. Specifically, in the corp domain, T-Extractor’s F1- measure approached that of the HAMLET model, lagging by 3.7%. In addition, the method showed results comparable to those of promtATE and TALN-LS2N.
Kalykulova A., Nugumanova A. //Informatica. – 2025. – Т. 49. – №. 2.