1. Подготовленная в результате реализации проекта научно-техническая продукция:
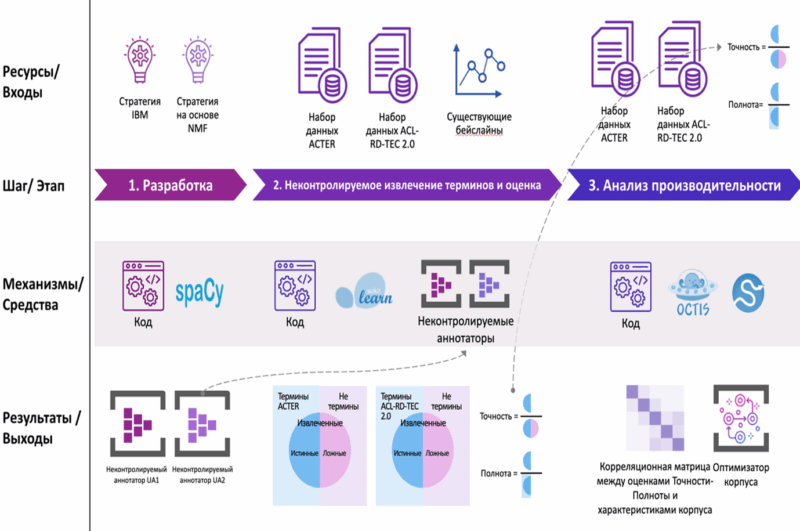
- Разработаны эффективные неконтролируемые аннотаторы UA1 и UA2.
- Получены оценки производительности аннотаторов UA1 и UA2 на наборах данных ACTER и ACL RD-TEC 2.0.
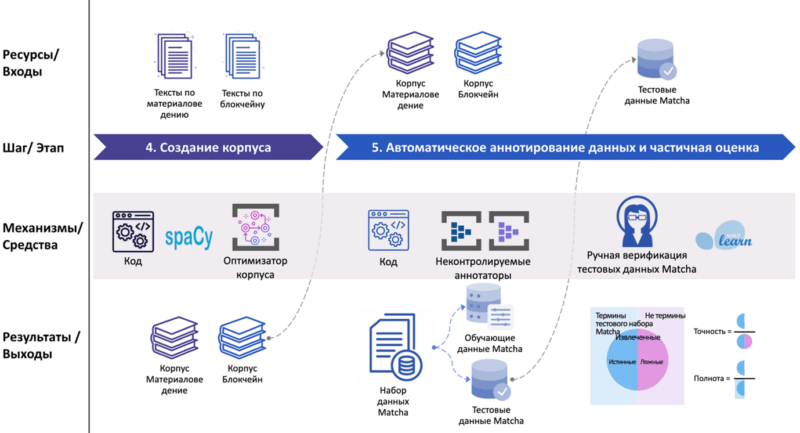
- Разработан эффективный оптимизатор корпуса текстов.
- Создан набор данных Matcha в доменах «Материаловедение» и «Блокчейн» на английском и казахском языках.
- Оценена производительность аннотаторов UA1 и UA2 на тестовом подмножестве набора данных Matcha.
- Разработан новый метод извлечения терминов T-Extractor.
2. Научные публикации:
1. Semantic Non-Negative Matrix Factorization for Term Extraction
В данном исследовании представлен подход к несупервизированному извлечению терминов, сочетающий метод неотрицательной матричной факторизации (NMF) с векторными представлениями слов. Вдохновившись одной из первых семантических реализаций NMF, в которой используется регуляризация для совместной оптимизации матриц «документ–слово» и «слово–слово» в задачах кластеризации документов, мы адаптировали эту стратегию для задачи извлечения терминов. Обычно матрица «слово–слово», отражающая семантические связи между словами, формируется на основе косинусного сходства между эмбеддингами слов. Однако известно, что эмбеддинги, полученные с помощью трансформеров, располагаются в узком конусе в векторном пространстве, из-за чего большинство пар слов демонстрируют завышенное сходство. Чтобы устранить этот эффект, мы заменяем стандартную матрицу «слово–слово» на матрицу «слово–ядро» (word–seed), ограничивая столбцы набором «доменных семян» — ключевыми словами, отражающими сущностные семантические характеристики конкретной предметной области. Таким образом, мы предлагаем модифицированную схему NMF, которая совместно факторизует матрицы «документ–слово» и «слово–ядро», что позволяет получить более точные векторные представления слов, используемые для извлечения тематически значимых терминов. Данная модификация существенно повышает эффективность извлечения терминов и представляет собой первое специализированное семантическое расширение NMF, адаптированное под задачу терм-экстракции. Сравнительные эксперименты показали, что предложенный метод превосходит как традиционные подходы на основе NMF, так и современные трансформерные решения, такие как KeyBERT и BERTopic. Для поддержки дальнейших исследований мы также собрали и вручную аннотировали два новых корпуса, каждый из которых содержит по 1000 предложений, в тематике «География и история» и «Национальные герои». Эти наборы пригодны как для извлечения терминов, так и для задач классификации документов. Весь исходный код и данные доступны в открытом доступе.
Nugumanova A. et al. Semantic Non-Negative Matrix Factorization for Term Extraction //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 7. – С. 72. doi.org/10.3390/bdcc8070072.
2. QA-RAG: Exploring LLM reliance on external knowledge
Крупные языковые модели (LLMs) способны хранить фактические знания в своих параметрах и демонстрируют высокие результаты в задачах ответа на вопросы. Однако остаются нерешёнными такие проблемы, как отсутствие прозрачности в объяснении полученных ответов (provenance) и ограниченность в актуализации знаний. Некоторые подходы стремятся преодолеть эти ограничения путём объединения параметрической памяти модели с внешними источниками знаний. В отличие от таких гибридных методов, наше предложенное решение QA-RAG полностью опирается на внешнюю базу знаний, а именно — на плотный векторный индекс (dense vector index database). В данной статье мы сравниваем конфигурации RAG с использованием двух языковых моделей Llama 2 — 7b и 13b, систематически оценивая их производительность по трём ключевым аспектам: устойчивость к шуму, выявление пробелов в знаниях и интеграция внешней достоверной информации. Результаты оценки показали, что предложенный подход достигает точности 83,3%, демонстрируя высокую эффективность по сравнению с существующими базовыми методами. Тем не менее, модель по-прежнему сталкивается с серьёзными трудностями при интеграции внешней правды (external truth), что указывает на необходимость дальнейших исследований и доработок. Полученные выводы подчеркивают, что, несмотря на перспективность RAG-архитектуры для задач вопросно-ответных систем, требуется значительный прогресс, чтобы максимально эффективно использовать её потенциал.
Mansurova A., Mansurova A., Nugumanova A. QA-RAG: Exploring LLM reliance on external knowledge //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 9. – С. 115. doi.org/10.3390/bdcc8090115.
3. Development of a question answering chatbot for blockchain domain.
Крупные языковые модели (LLMs), такие как ChatGPT, радикально изменили область обработки естественного языка благодаря своей способности к пониманию и генерации связных, человекоподобных ответов во множестве прикладных задач. Несмотря на впечатляющие возможности, они часто демонстрируют ограничения в специализированных и насыщенных знаниями областях, главным образом из-за отсутствия доступа к релевантной информации. Более того, большинство современных LLM доступны лишь через API, что ограничивает прозрачность их внутренней работы. Применение таких моделей в критически важных сценариях также затруднено из-за склонности к генерации недостоверной (галлюцинирующей) информации и неспособности использовать внешние источники знаний. Для преодоления этих ограничений в настоящем исследовании предлагается инновационная система, расширяющая возможности LLM за счёт интеграции с внешним модулем управления знаниями. Данная система позволяет языковым моделям использовать данные, хранящиеся в векторных базах данных, что обеспечивает доступ к релевантной информации для формирования более точных ответов. Кроме того, система поддерживает извлечение информации из интернета, тем самым значительно расширяя фактическую базу знаний модели.
Предложенный подход позволяет обойти необходимость повторного обучения LLM, что представляет собой ресурсозатратный процесс. Вместо этого делается акцент на более эффективном использовании уже существующих моделей. Предварительные результаты демонстрируют потенциал системы в повышении эффективности языковых моделей в предметно-ориентированных и знания-интенсивных задачах. Оснастив LLM возможностью в реальном времени обращаться к внешним источникам данных, можно значительно повысить их прикладную ценность, не прибегая к постоянному увеличению размеров самих моделей.
Mansurova A., Nugumanova A., Makhambetova Z. Development of a question answering chatbot for blockchain domain //Scientific Journal of Astana IT University. – 2023. – С. 27-40. doi.org/10.37943/15XNDZ6667.
4. Evaluation Of IBM’s Proposed Term Extraction Approach On The ACTER Corpus
Автоматическое извлечение терминов стремится к повышению эффективности и точности. Исследователи IBM предложили метод несупервизированной аннотации, направленный на извлечение специализированных терминов в технических доменах. Этот подход использует энкодеры предложений и анализ морфологических признаков, связей между терминами и темами, а также семантического сходства между терминами. В данной работе мы реализуем предложенный IBM метод «с нуля» и проводим тестирование на корпусе ACTER. Кроме того, в рамках эксперимента мы проводим анализ извлечения некорректных n-грамм, способных негативно повлиять на качество несупервизированного аннотирования. Воспроизведённый нами метод продемонстрировал значение F1-метрики 44,8% и потерю в 5,15% по сравнению с оригинальным подходом IBM на корпусе ACL-RD-TEC 2.0. На корпусе ACTER наши метрики показали схожие результаты с другими передовыми методами, ранее применёнными к этому датасету.
Kalykulova A., Kairatuly B., Rakhymbek K., Kyzyrkanov A., Nugumanova A. Evaluation Of IBM’s Proposed Term Extraction Approach On The ACTER Corpus // IX — International Scientific Conference «Computer Science and Applied Mathematics». — Almaty: Institute of Information and Computational Technologies CS MSHE RK, 2024. — С. 597–604. https://conf.iict.kz/wp-content/uploads/2025/01/collection_CSAM_IX_2024.pdf
5. Оценка и сравнение качества эмбеддингов слов
Эмбеддинги слов играют ключевую роль в современных методах обработки естественного языка (NLP). В данной статье рассматриваются методы оценки качества эмбеддингов, которые можно разделить на внутренние и внешние. Внутренние методы оценивают представления вне контекста конкретных задач, тогда как внешние методы используют задачи NLP для оценки. Основное внимание уделяется оценке семантического сходства с использованием наборов данных WordSim-353, SimLex- 999 и SimVerb-3500. Для оценки были использованы предобученные модели FastText и SentenceBERT. Результаты показывают, что модели FastText демонстрируют высокие коэффициенты корреляции и превосходят SentenceBERT в задаче представления отдельных слов. SentenceBERT, несмотря на свои преимущества в задачах поиска семантического сходства и кластеризации, менее эффективен для отдельных слов. Выбор модели должен основываться на эмпирических данных и специфических требованиях задачи.
Альжанов А. М., Рахымбек К. К. Оценка и сравнение качества эмбеддингов слов // Проблемы оптимизации сложных систем: Материалы XX Междунар. Азиат. школы-семинара. – Алматы, 2024. – С. 211–215. https://conf.iict.kz/wp—content/uploads/2024/09/opcs_material_2024.pdf.
6. T-Extractor: A Hybrid Unsupervised Approach for Term and Named Entity Extraction Using Rules, Statistical, and Semantic Methods
Автоматическое извлечение терминов является ключевой технологией для оптимизации задач обработки естественного языка, таких как машинный перевод, анализ тональности текста, построение графа знаний и/или заполнение онтологий. В этом исследовании представлен подход T-Extractor для неконтролируемого извлечения терминов. Цель исследования — разработать эффективный метод, не требующий размеченных данных, и проанализировать его применимость к научным текстам. T-Extractor объединяет основанный на правилах, статистический и семантический анализ, рассматривая извлечение униграмм и фраз как две подзадачи. Шаблоны частей речи используются на этапе выбора кандидатов, в то время как фильтр, основанный на необработанных и исправленных частотах, уточняет границы фраз. TopicScore применяется для окончательной фильтрации терминов, повышая точность извлечения. Кроме того, простые правила помогают идентифицировать сокращения и именованные сущности, улучшая полноту. T-Extractor был протестирован на наборах данных ACTER (три языка, четыре домена) и ACL RD-TEC 2.0. В английском языке наилучший результат был достигнут в области equi с F1-мерой 48,5%, точностью 41,6% и полнотой 58,2%. На наборе данных ACTER подход превзошёл существующие неконтролируемые методы и показал результаты лучше контролируемых моделей GPT-3.5-Turbo и BERT в областях corp и wind. В частности, в области corp F1-мера T-Extractor приблизилась к модели HAMLET, отстав на 3,7%. Кроме того, метод показал результаты, сопоставимые с результатами promtATE и TALN-LS2N.
Kalykulova A., Nugumanova A. //Informatica. – 2025. – Т. 49. – №. 2.