1. Жобаны іске асыру нәтижесінде дайындалған ғылыми-техникалық өнімдер:
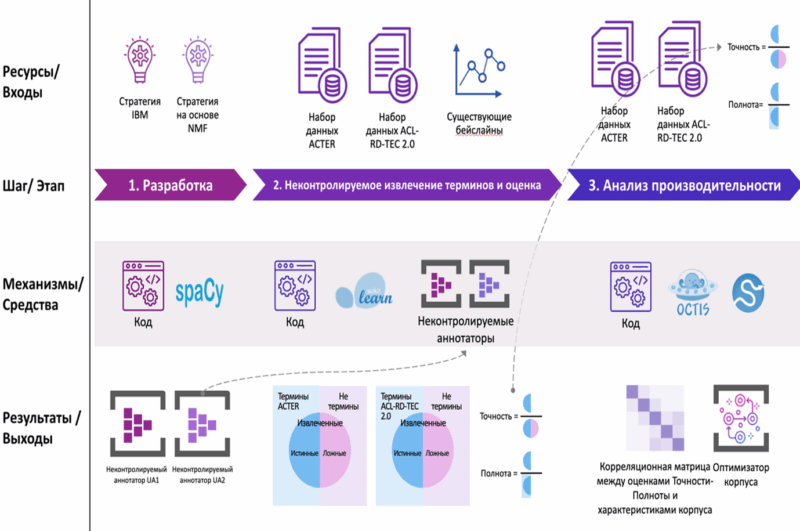
- UA1 және UA2 тиімді бақылаусыз аннотациялаушылар әзірленді;
- UA1 және UA2 аннотациялаушыларының өнімділігі ACTER және ACL RD-TEC 2.0 деректер жиынтықтарында бағаланды;
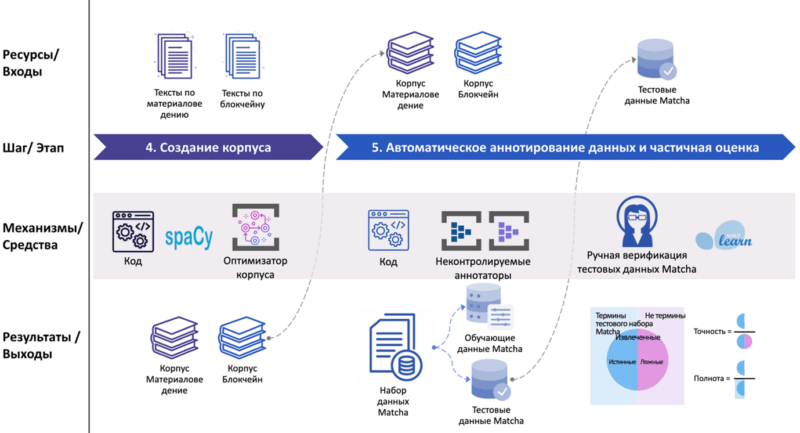
- Мәтін корпустарын оңтайландыруға арналған тиімді құрал жасалды;
- Материалтану және Блокчейн салаларына арналған Matcha деректер жиынтығы ағылшын және қазақ тілдерінде құрылды;
- Matcha деректер жиынтығының тестілік ішкі жиынтығында UA1 және UA2 аннотациялаушыларының өнімділігі бағаланды;
- Терминдерді бөліп алуға арналған жаңа әдіс — T-Extractor жасалды.
2. Ғылыми жарияланымдар:
1. Терминдерді бөліп алуға арналған семантикалық бейтарап матрицалық жіктеу
Бұл зерттеуде терминдерді бақылаусыз бөліп алуға арналған жаңа әдіс ұсынылады. Ол бейтарап матрицалық жіктеу (NMF) мен сөз эмбеддингтерін біріктіреді. Әдістің негізі – құжаттарды кластерлеу үшін құжат–сөз және сөз–сөз матрицаларын бірлесіп оңтайландыратын, ерте ұсынылған семантикалық NMF тәсілінен шабыт алған. Терминдерді бөліп алу міндетіне бұл стратегия алғаш рет бейімделіп отыр.
Кәдімгі тәсілде сөздер арасындағы семантикалық байланыстарды сипаттайтын сөз–сөз матрицасы сөз эмбеддингтерінің арасындағы косинустық ұқсастықтарға сүйене отырып құрастырылады. Алайда трансформер энкодерлері арқылы алынған эмбеддингтер векторлық кеңістікте тар конус ішінде орналасатыны дәлелденген, бұл барлық сөз жұптары арасында жоғары ұқсастық көрсеткішіне әкеледі.
Осы мәселені шешу үшін, біз дәстүрлі сөз–сөз матрицасын «сөз–тұқым» (word–seed) ішкі матрицамен алмастырамыз. Бұл ішкі матрицада тек доменге тән мағыналық тұрғыдан маңызды сөздер — «домен тұқымдары» пайдаланылады. Осылайша, біз құжат–сөз және сөз–тұқым матрицаларын бірлесіп жіктеуге мүмкіндік беретін жаңартылған NMF шеңберін ұсынамыз. Бұл тәсіл сөздердің дәлірек векторлық көріністерін алуға және тақырыптық тұрғыдан маңызды терминдерді тиімдірек бөліп алуға мүмкіндік береді.
Ұсынылған әдіс терминдерді бөліп алудың тиімділігін айтарлықтай арттырып, осы тапсырмаға арнайы бейімделген семантикалық NMF тәсілінің алғашқы іске асырылуы болып табылады. Салыстырмалы эксперименттер нәтижесінде бұл әдіс дәстүрлі NMF және заманауи трансформерге негізделген KeyBERT пен BERTopic әдістерінен асып түскені көрсетілді.
Бұдан бөлек, болашақ зерттеулер мен тәжірибелік қолданбалар үшін «География және тарих» және «Ұлттық батырлар» тақырыптарынан алынған 1000 сөйлемнен тұратын екі жаңа корпус жиналып, қолмен аннотацияланды. Бұл деректер жиынтықтары әрі терминдерді бөліп алу, әрі құжаттарды классификациялау міндеттері үшін пайдалы. Барлық код пен деректер ашық қолжетімді.
Nugumanova A. et al. Semantic Non-Negative Matrix Factorization for Term Extraction //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 7. – С. 72. doi.org/10.3390/bdcc8070072.
2. QA-RAG: Үлкен тілдік модельдердің (LLM) сыртқы білімге тәуелділігін зерттеу
Ірі тілдік модельдер (LLM) өз параметрлерінде фактілік білімді сақтай алады және сұрақ-жауап (QA) міндеттерінде жоғары нәтижелерге қол жеткізуде. Алайда, мұндай модельдер қабылдаған шешімдердің дереккөзін дәлелдеу (provenance) және білімдерін өзектендіру мәселелері әлі де өзекті болып отыр. Бұл шектеулерді еңсеру үшін кейбір тәсілдер модельдің ішкі жадысын сыртқы білім көздерімен біріктіруді көздейді.
Біздің ұсынып отырған QA-RAG шешімі бұл тұрғыда өзгеше: ол тек сыртқы білім базасына — тығыз векторлық индекстелген деректер қорына — сүйенеді. Осы мақалада біз екі LLM моделін — Llama 2 7b және Llama 2 13b— пайдалана отырып, түрлі RAG конфигурацияларын салыстырып, олардың өнімділігін RAG архитектурасының үш негізгі қабілеті бойынша жүйелі түрде бағаладық:
- Шуға төзімділік (noise robustness)
- Білімдегі олқылықтарды анықтау (knowledge gap detection)
- Сыртқы шынайы ақпаратты біріктіру (external truth integration)
Бағалау нәтижелері біздің тәсілдің 83,3% дәлдікке қол жеткізгенін көрсетті, бұл барлық базалық әдістермен салыстырғанда жоғары тиімділікті білдіреді. Дегенмен, модельдің сыртқы шынайы ақпаратты интеграциялау қабілеті әлі де әлсіз екені байқалды.
Бұл нәтижелер сұрақ-жауап жүйелерінде RAG архитектурасын толыққанды және сенімді пайдалану үшін қосымша зерттеулер мен әдістемелік жетілдірулер қажет екенін көрсетеді.
Mansurova A., Mansurova A., Nugumanova A. QA-RAG: Exploring LLM reliance on external knowledge //Big Data and Cognitive Computing. – 2024. – Т. 8. – №. 9. – С. 115. doi.org/10.3390/bdcc8090115.
3. Блокчейн саласы үшін сұрақ-жауап чат-ботын әзірлеу
ChatGPT секілді ірі тілдік модельдер (LLM) табиғи тілді өңдеу (NLP) саласында төңкеріс жасап, адамға ұқсас, мәнерлі жауаптарды генерациялау және тілдік мазмұнды түсіну қабілеті арқылы көптеген қолданбалы міндеттерді орындауда жоғары нәтижелерге қол жеткізді. Алайда, осындай әсерлі мүмкіндіктеріне қарамастан, бұл модельдер салаға тән және білімге бай домендерде жиі әлсіздік танытады, себебі оларда сол салаларға қатысты нақты деректерге қол жеткізу шектеулі.
Сонымен қатар, қазіргі заманғы LLM модельдерінің көпшілігі тек API арқылы қолжетімді және ішкі жұмыс механизмдері бойынша мөлдірлік деңгейі төмен. Мұндай модельдердің шынайы өмірдегі маңызды міндеттерде қолданылуын шектейтін тағы бір мәселе — галлюцинацияланған (жалған немесе дәл емес) ақпарат тудыруы және сыртқы білім көздерін пайдалана алмауы.
Осы шектеулерді жою үшін біз LLM модельдерін сыртқы білімді басқару модулімен біріктіру арқылы олардың мүмкіндіктерін кеңейтетін инновациялық жүйе ұсынамыз. Ұсынылған жүйе LLM-дерге векторлық деректер базасында сақталған мәліметтерді пайдалануға мүмкіндік береді, бұл олардың жауаптарының мазмұнын нақты әрі өзекті етуге жағдай жасайды. Сонымен қатар, жүйе Интернеттен ақпарат іздеп алуға да мүмкіндік береді, осылайша модельдің білім базасы кеңейеді.
Ұсынылып отырған тәсіл LLM модельдерін қайта оқытуды қажет етпейді — бұл процесс ресурстық тұрғыдан қымбат әрі күрделі болуы мүмкін. Оның орнына, бар модельдерді барынша тиімді қолдануға басымдық беріледі.
Алғашқы тәжірибелік нәтижелер көрсеткендей, бұл жүйе салаға бейімделген және білімге тәуелді міндеттерде LLM өнімділігін арттырудың келешегі бар екенін дәлелдейді. LLM-дерге нақты уақытта сыртқы деректерге қол жеткізу мүмкіндігін беру арқылы үлкен модельдерге көшу қажеттілігінсіз-ақ олардың генерациялау қабілетін тиімді пайдалануға болады.
Mansurova A., Nugumanova A., Makhambetova Z. Development of a question answering chatbot for blockchain domain //Scientific Journal of Astana IT University. – 2023. – С. 27-40. doi.org/10.37943/15XNDZ6667.
4. IBM ұсынған терминдерді бөліп алу әдісін ACTER корпусында бағалау
Автоматтандырылған терминдерді бөліп алу – тиімділігі мен дәлдігі жоғары әдістерді талап ететін зерттеу бағыты. IBM зерттеушілері техникалық домендерге тән терминдерді бөліп алуға арналған бақылаусыз аннотациялаушыны ұсынды. Бұл тәсіл сөйлемдік энкодерлерді, морфологиялық белгілерді, термин мен тақырып арасындағы байланыстарды және терминдердің ішкі ұқсастықтарын талдауды қамтиды.
Осы мақалада біз IBM ұсынған әдісті толықтай нөлден бастап қайта жүзеге асырып, оны ACTER деректер жиынтығында тестілеуден өткіздік. Эксперимент барысында біз сондай-ақ қате бөлінген n-граммалардың әсерін талдадық — бұл бақылаусыз аннотациялаушының сапасына кері әсер етуі мүмкін фактор.
Қайта жүзеге асырылған әдіс ACL-RD-TEC 2.0 деректер жиынтығында IBM тәсілімен салыстырғанда F1-мәні 44,8% және 5,15% өнімділік шығынын көрсетті. Ал ACTER корпусында алынған метрикалар бұл саладағы басқа заманауи әдістермен салыстырғанда ұқсас нәтижелер берді.
Бұл зерттеу IBM тәсілінің қайта құрылымдалған нұсқасының тиімділігін көрсетіп, бақылаусыз терминдерді бөліп алу әдістерін жетілдіруге қосымша дереккөз болып табылады.
Kalykulova A., Kairatuly B., Rakhymbek K., Kyzyrkanov A., Nugumanova A. Evaluation Of IBM’s Proposed Term Extraction Approach On The ACTER Corpus // IX — International Scientific Conference «Computer Science and Applied Mathematics». — Almaty: Institute of Information and Computational Technologies CS MSHE RK, 2024. — С. 597–604. https://conf.iict.kz/wp-content/uploads/2025/01/collection_CSAM_IX_2024.pdf
5. Сөз эмбеддингтерінің сапасын бағалау және салыстыру
Сөз эмбеддингтері қазіргі заманғы табиғи тілді өңдеу (NLP) әдістерінде маңызды рөл атқарады. Бұл мақалада эмбеддинг сапасын бағалаудың әртүрлі тәсілдері қарастырылады, оларды ішкі (intrinsic) және сыртқы (extrinsic)әдістерге бөлуге болады. Ішкі әдістер эмбеддингтерді нақты тапсырмалар контекстінен тыс бағаласа, сыртқы әдістер оларды нақты NLP міндеттерінде қолдану арқылы бағалайды.
Негізгі назар семантикалық ұқсастықты бағалауға аударылған, ол үшін WordSim-353, SimLex-999 және SimVerb-3500 деректер жиынтықтары қолданылды. Бағалау процесінде алдын ала оқытылған FastText және SentenceBERT модельдері пайдаланылды.
Нәтижелерге сәйкес, FastText модельдері жоғары корреляция коэффициенттерін көрсетті және жеке сөздерді көрсету (representation) міндетінде SentenceBERT моделінен асып түсті. Ал SentenceBERT моделі семантикалық ұқсастықты іздеу мен кластерлеу тапсырмаларында тиімді болғанымен, жеке сөздерге қатысты нәтижелері төмендеу болды.
Зерттеу қорытындысы бойынша, модельді таңдау эмпирикалық деректерге және нақты қолдану міндетінің ерекшеліктеріне сүйеніп жүргізілуі тиіс.
Альжанов А. М., Рахымбек К. К. Оценка и сравнение качества эмбеддингов слов // Проблемы оптимизации сложных систем: Материалы XX Междунар. Азиат. школы-семинара. – Алматы, 2024. – С. 211–215. https://conf.iict.kz/wp-content/uploads/2024/09/opcs_material_2024.pdf.
6. T-Extractor: A Hybrid Unsupervised Approach for Term and Named Entity Extraction Using Rules, Statistical, and Semantic Methods
Терминдерді автоматты түрде шығару – машиналық аударма, сезімді талдау, білім графигін құру және/немесе онтологияны толтыру сияқты табиғи тілді өңдеу тапсырмаларын оңтайландырудың негізгі технологиясы. Бұл зерттеу бақыланбайтын терминді алу үшін T-Extractor әдісін ұсынады. Зерттеудің мақсаты таңбаланған деректерді қажет етпейтін тиімді әдісті әзірлеу және оның ғылыми мәтіндерге қолданылуын талдау. T-Extractor ережеге негізделген, статистикалық және семантикалық талдауды біріктіреді, оны униграмма мен фразаны екі қосалқы тапсырма ретінде қарастырады. Үміткерді таңдау қадамында сөз бөлігі үлгілері пайдаланылады, ал өңделмеген және түзетілген жиіліктерге негізделген сүзгі фразалар шекараларын нақтылайды. TopicScore соңғы тоқсанды сүзу үшін қолданылады, бұл шығару дәлдігін жақсартады. Сонымен қатар, қарапайым ережелер аббревиатуралар мен аталған нысандарды анықтауға көмектеседі, еске түсіруді жақсартады. T-Extractor ACTER (үш тіл, төрт домен) және ACL RD-TEC 2.0 деректер жиынында сынақтан өтті. Ағылшын тілінде ең жақсы нәтиже F1-балы 48,5%, дәлдік 41,6% және қайта шақыру 58,2% болатын equi доменінде қол жеткізілді. ACTER деректер жинағында тәсіл бұрыннан бар бақыланбайтын әдістерден асып түсті және корпус пен жел домендеріндегі бақыланатын GPT-3.5-Turbo және BERT үлгілерінен асып түсті. Атап айтқанда, корпоративтік доменде T-Extractor-тың F1-балы HAMLET үлгісіне жақындап, 3,7%-ға артта қалды. Сонымен қатар, әдіс promtATE және TALN-LS2N нәтижелерімен салыстырылатын нәтижелер көрсетті.
Kalykulova A., Nugumanova A. //Informatica. – 2025. – Т. 49. – №. 2.